Spuriosity Didn't Kill the Classifier: Using Invariant Predictions to Harness Spurious Features
Abstract
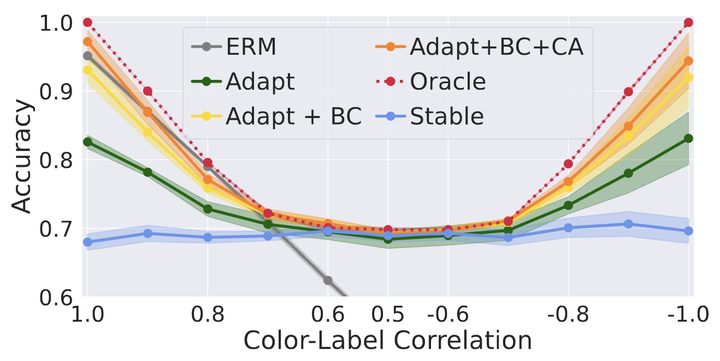
To avoid failures on out-of-distribution data, recent works have sought to use only features with an invariant or stable relationship with the label across domains, discarding spurious or unstable features whose relationship with the label changes across domains. However, unstable features often carry complementary information about the label that could boost performance if used correctly in the test domain. Our main contribution is to show that it is possible to learn how to use these unstable features in the test domain without labels. We prove that pseudo-labels based on stable features provide sufficient guidance for doing so, provided that stable and unstable features are conditionally independent given the label. Based on this insight, we propose Stable Feature Boosting (SFB), an algorithm for: (i) learning stable and conditionally-independent unstable features; and (ii) using the stable-feature predictions to adapt the unstable-feature predictions to the test domain. Theoretically, we prove that SFB can learn an asymptotically-optimal predictor without test-domain labels. Empirically, we demonstrate the effectiveness of SFB on real and synthetic data.
Andrei Liviu Nicolicioiu
PhD student - Machine Learning Researcher
Machine Learning and Computer Vision Researcher.